알고리즘?
컴퓨터에게 내리는 지시사항을 나열한 것
시간 복잡도?
시간 복잡도는 n개의 입력 데이터에 대해 알고리즘이 문제를 해결하는데에 얼만큼의 시간(걸리는 절차 수)이 걸리는지를 나타내는 것을 말한다.
일반적으로 시간 복잡도를 나타내기 위해 점근적 표기법(asymptotic notation)을 사용한다.
- 점근적 표기법 - 중요하지 않은 상수와 계수들을 제거해 알고리즘의 실행 시간에서 중요한 성장률에 집중하는 방법을 의미함
- 점근적이라는 의미는 가장 큰 영향을 주는 요소만 계산한다는 의미
점근적 표기법에는 다음과 같은 세가지가 존재한다.
- 오메가 표기법(Big-Ω notation)
- 세타 포기법(Big-θ notation)
- 빅오 표기법(Big-O notation)
효율적인 방법을 고민한다는 것은 시간 복잡도를 고민하는 것과 같다.
Big-O 표기법
빅오 표기법은 알고리즘의 시간 복잡도와 공간 복잡도를 나타내는데 사용된다.
- 시간복잡도는 입력된 N의 크기에 따라 실행되는 알고리즘 단계의 수를 나타낸다.
- 공간복잡도는 알고리즘이 실행될 때 사용하는 메모리의 양을 나타낸다.
시간 복잡도를 각각 최악, 최선, 중간(평균)의 경우에 표기하는 방법으로 불필요한 연산을 제거하고 알고리즘 분석을 쉽게한 목적으로 사용된다.
| 최상 | Big-Ω(빅-오메가) | 하한 점근 |
| 평균 | Big-θ(빅-세타) | 최상과 최악의 평균 |
| 최악 | Big-O(빅-오) | 상한 점근 |
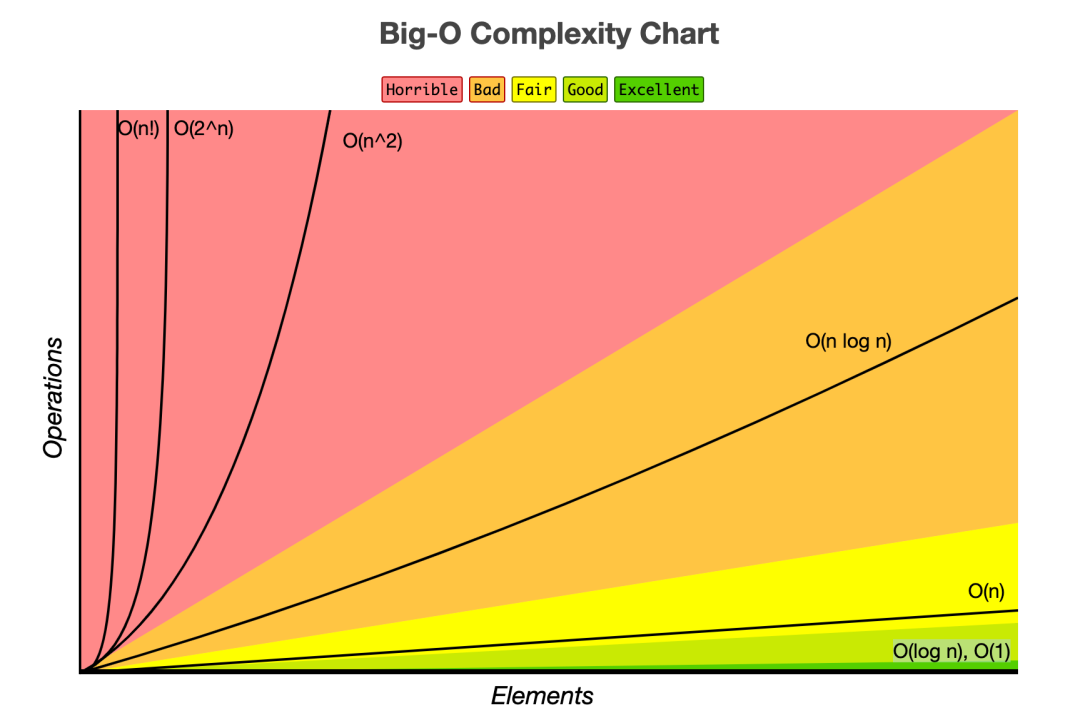
시간복잡도는 다른 의미로 알고리즘을 수행하기 위해 프로세스가 수행해야만 하는 연산을 수치화한 것이다.
시간복잡도에서 가장 중요하게 보는 것은 가장 큰 영향을 미치는 n의 단위이다.
| 복잡도 | 1 | 10 | 100 |
| O(1) | 1 | 1 | 1 |
| O(log N) | 0 | 2 | 5 |
| O(N) | 1 | 10 | 100 |
| O(N log N) | 0 | 20 | 461 |
| O(N^2) | 1 | 100 | 10000 |
| O(2^N) | 1 | 1024 | 1267650600228229401496703205376 |
| O(!N) | 1 | 3628800 | 화면에 표현할 수 없음! |
O(1) : 상수
알고리즘이 문제를 해결하는 데에 필요한 단계의 수가 오직 한단계인 경우
즉, 입력 데이터의 개수와 관계없이 처리 시간 또는 메모리 사용량이 일정하다.
O(N) : 선형
알고리즘이 문제를 해결하는 데에 필요한 단계의 수가 입력 데이터의 개수 N에 비례하는 경우
즉, 입력 데이터의 개수에 따라 처리 시간 또는 메모리 사용량이 선형적으로 증가
O(N*N)
알고리즘이 문제를 해결하기 위해 필요한 단계의 수가 입력 데이터의 개수 N의 제곱인 경우
이진 검색 : 정렬 알고리즘
O(log N) : 로그 시간
알고리즘이 문제를 해결하기 위해 필요한 단계의 수가 연산마다 특정 요인에 의해 감소하는 경우
O(N log N)
이진 검색 : 정렬 알고리즘
O(Cn): 지수 시간
알고리즘이 문제를 해결하는데에 피요한 단계의 수가 주어진 상수 값 C의 n 제곱인 경우
| 1 | 10 | 100 | |
| 1 | 1 | 1 | |
| 0 | 2 | 5 | |
| 1 | 10 | 100 | |
| 0 | 20 | 461 | |
| 1 | 100 | 10000 | |
| 1 | 1024 | 1267650600228229401496703205376 | |
| 1 | 3628800 | 화면에 표시 불가 |
정렬 알고리즘 별 Big-O 비교
| Sorting Algorithm | 최선 | 평균 | 최악 |
| Bubble Sort(버블 정렬) | O(n2) | O(n2) | |
| Heap Sort(힙 정렬) | O(n log n) | O(n log n) | |
| Insertion Sort(삽입 정렬) | |||
| Merge Sort(합병 정렬) | O(n log n) | O(n log n) | |
| Quick Sort(퀵 정렬) | O(n log n) | ||
| Selection Sort(선택 정렬) | |||
| Shell Sort(셸 정렬) | |||
| Smooth Sort(부드러운 정렬) |
** Bubble Sort(버블 정렬) - 매번 연속된 두 개의 인덱스를 비교하여, 정한 기준의 값을 뒤로 넘겨 정렬하는 방식(1,2번을 비교해 큰 값을 뒤로 넘김)
** Heap Sort(힙 정렬) - 내림 차순 정렬을 위해서 최대 힙을 구성하고 오름 차순 정렬을 위해서 최소 힙을 구성한다. (힙? 이진 트리의 일종으로 우선순위 큐를 위하여 만들어진 자료구조로 최대값 최소값을 쉽게 추출할 수 있는 자료구조)
** Merge Sort(합병 정렬) - 큰 문제를 반으로 쪼개서 해결해 나가는 분할 방식으로 배열의 크기가 1보다 작거나 같을 때까지 반복
** Quick Sort(퀵 정렬) - 퀵 정렬, 분할 정복을 이용하여 정렬을 수행하는 알고리즘으로 기준이 되는 값을 정하고 그 값보다 작은 값은 왼쪽 큰 값은 오른쪽으로 정렬한다. 배열의 크기가 1보다 작거나 같을 때까지 반복
** Shell Sort(셸 정렬) - 삽입 정렬을 보완한 알고리즘으로 삽입 정렬과 다르게 전체의 리스트를 한번에 정리하지 않고 대신 먼저 정렬해야할 리스트를 일정한 기준에 따라 분류하여 연속적이지 않은 여러개의 부분 리스트를 만들고 각 부분 리스트에 삽입 정렬을 이용하여 정렬
** Smooth Sort(부드러운 정렬) - 힙 정렬의 변형 중 하나로 입력을 우선 순위 대기열로 구성한 다음 반복적으로 최대값을 추출한다.
자료 구조별 Big-O 비교
| Data Structure | ||||||
| Sorted Array | ||||||
| Array | N/A | N/A | N/A | N/A | ||
| Linked List | ) | |||||
| Doubly Linked List | ||||||
| Stack | ||||||
| Hash Table | ||||||
| Binary Search Tree | ||||||
| B-Tree | ||||||
| Red-Black Tree | ||||||
| AVL Tree |
시간 복잡도를 구하는 요령
- 하나의 루프를 사용하여 단일 요소 집합을 반복 하는 경우 : O (n)
- 컬렉션의 절반 이상을 반복 하는 경우 : O (n / 2) -> O (n)
- 두 개의 다른 루프를 사용하여 두 개의 개별 콜렉션을 반복 할 경우 : O (n + m) -> O (n)
- 두 개의 중첩 루프를 사용하여 단일 컬렉션을 반복하는 경우 : O (n²)
- 두 개의 중첩 루프를 사용하여 두 개의 다른 콜렉션을 반복 할 경우 : O (n * m) -> O (n²)
- 컬렉션 정렬을 사용하는 경우 : O(n*log(n))
'개념 정리' 카테고리의 다른 글
| package.json 작성하기 (0) | 2022.05.03 |
|---|---|
| 쿠키, 세션, 캐시, 토큰 (0) | 2022.05.02 |
| package.json과 package-lock.json 그리고 node_modules (0) | 2022.04.21 |
| 스택(STACK), 큐(QUEUE) (0) | 2022.04.19 |
| 폴리필(polyfill) (0) | 2022.02.07 |